
Machine learning – perhaps one of the more prominent buzzwords of recent times, and typically coupled with data science. In the simplest terms, machine learning is the way that computers “learn” and make predictions based on the data that we feed it (quite cannibalistic when put that way). The algorithms used are expertly designed to make purely data-driven decisions and predictions. Anyone who is the least bit interested in this topic has likely heard the phrase “Correlation doesn’t always mean causation”. What this machine learning algorithm aims to do is bring these two as close together as possible. Let’s take a look at one of the simpler algorithms put into practice – the simple linear regression model.
The Simple Linear Regression Model in Machine Learning
Simple linear regression isn’t a method which was designed explicitly for use within machine learning. In fact, simple linear regression is a statistical model which allows us to observe the relationship between two constant numerical variables. For example, grade percentage vs. hours studied, or yearly earnings vs. years in the workforce, etc. It aims to find the correlation between these two variables and in essence, the formula draws a “trend line” to show the correlation between the two variables. Here’s an example:
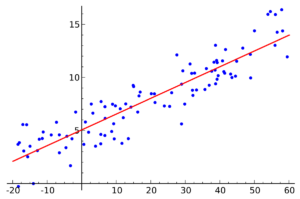
Now for sake of easy understanding lets imagine that the x-axis is the number of minutes that someone worked out. Then, the y-axis shows the amount (x100) of calories burned.
It would be common sense to understand that there’s a high correlation between minutes and calorie burn, however, how can we prove that numerically? This is where the machine learning algorithm comes into play. Now, there is also a case to be made in that this example doesn’t take into account the type of exercise performed. However, this requires a more advanced model using multiple linear regression (which is a whole other topic of discussion). With outliers aside, let’s dive into how this machine learning algorithm works.
How the Simple Linear Regression Model Works
As mentioned previously, simple linear regression is a statistical equation which determines the trend between x (the independent variable), and y (the dependent variable). The equation looks like this:
y = a + b * x

What we’re ultimately trying to understand is how one factor depends on something else. In this equation, b is the coefficient which shows how a unit change in x affects a unit change in y. So in the case of our exercise model, the equation looks as such: calories = a + b * minutes. Simple linear regression will find the absolute best line to fit the trend within this data.
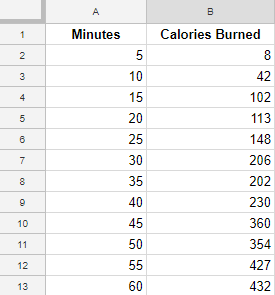
Here is some dummy data which we can use to easily visualize how machine learning would put this into practice. Let’s imagine the data points are taken from one individual on different days of working out as well.
How is a machine learning algorithm carried out?
Most machine learning models execute using programming languages. Seemingly the most popular language for this task is Python. A popular distribution for data science is an open source software known as Anaconda which you can find more information about on their website. The goal here isn’t to learn all about Python or how to actually write the algorithm using a data set, but to rather understand the cogs and wheels that make it turn. Here are the steps one would take to perform this machine learning algorithm:
Step 1: Importing your data
The first step is to import the data into your model. In our case, we would import the above CSV containing the table for minutes (the independent variable) and calories burned (the dependent variable).
Step 2: Data preprocessing
This step is absolutely crucial in machine learning. To accurately train a model, you need to split your data into two different sets – training, and a test set. What this allows is for the algorithm to “learn” based on the training set. This typically consists of around 80% of the total data, and then make predictions on the remaining 20%. That way, the predicted results won’t fit exactly to the data, but rather more accurate predictions will draw themselves from the training set. Within the algorithm, our data would now look something like this. Random pieces of our data are now in either the training or test set (75/25 split).
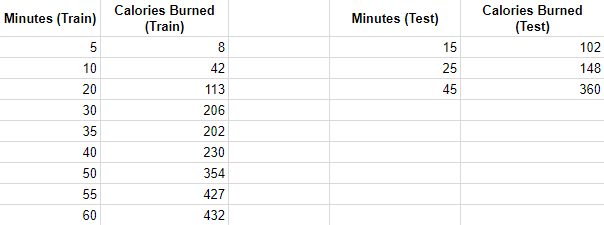
Preprocessing also includes a variety of other steps. However, for the simple linear regression model, splitting the data is the main focus.
Step 3: Perform the algorithm and observe the data

There are a number of libraries within the Python language which help machine learning experts carry out the algorithms. Many are used simply by instantiating classes and using methods from those classes which will do all of the calculations behind the scenes. Once the heavy math is complete, it becomes time to plot the actual data and observe the predicted values. If we were to observe the results of this machine learning algorithm on our workout dummy data, we would now be able to see a calculated trend line.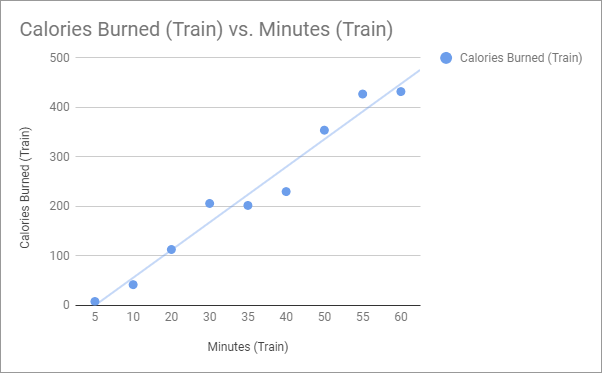
And there you have it, this is the simple linear regression model at work. A properly performed machine learning model will give you the trend line based on the newly predicted values. This is exactly how researchers, businesses, and many others make data-driven decisions.
How far do machine learning algorithms go?
The simple linear regression model is simply scratching the surface of machine learning. In fact, many debate this to be an irrelevant part of machine learning. Since SLR is quite easy to visualize, one could even make assumptions with the naked eye. Although, the method is still a great starting point for seeing how machine learning involves statistical computation. These techniques make intelligent decisions and provide invaluable data for every-day life.
Use promo code “SKY95ML” to save 95% off your first month. Offer is valid for new users only.
READ MORE:
How to Connect an iOS App to a MySQL Database
Common Cloud Computing Use Cases
Digital Transformation as it Applies to your Business
10 Advantages to Cloud Computing for Small to Medium Businesses





